An overview of YepCode technology stack

Discover YepCode technology stack
Divide et impera… microservices to the rescue!
The planning process for building the YepCode technology stack was thorough and deliberate. We had no doubt about the benefits of creating YepCode using microservices instead of a monolithic architecture: scalability, resource efficiency, automation (CI/CD), reliability, isolated and bulletproof environments, and maintainability.
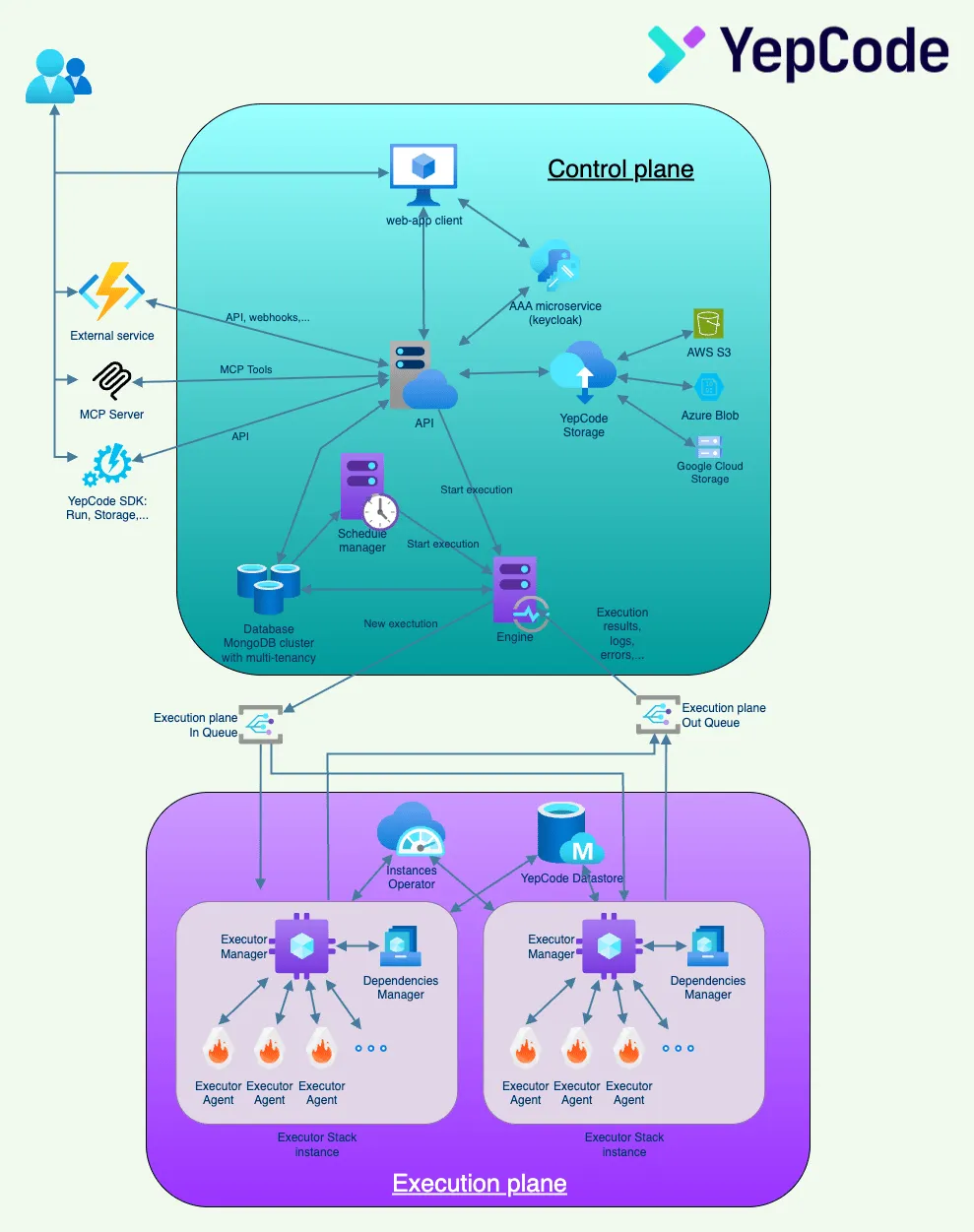
In the following image, you can see YepCode’s current microservices architecture diagram. In the next sections, we’ll provide an overview of each service, explaining the technologies, responsibilities, and communications between them.
Before starting, a little bit of DDD, testing, hexagonal architecture, git branching model, CI/CD…
As you might expect, in YepCode we are code lovers, and we like to create software using high-quality standards. Some of the principles we apply on every YepCode layer are:
- DDD: We need to understand that software is not just about code. Domain-Driven Design ensures that every person involved in the project speaks the same language. Sometimes it’s hard to communicate, but once that barrier is broken, information flows freely and doesn’t get lost. DDD provides a guide for both strategic and tactical design. Strategic focus centers on business values, while tactical focus builds a battle-tested domain model. DDD also emphasizes practices like continuous integration. This ensures the integrity of the entire project, allowing potential problems to be detected early.
- Testing: We want every piece of code to be fully tested. We know that’s somewhat idealistic, but we do our best. Every feature has its unit, integration, acceptance, and smoke tests. Developing a function without any test is not acceptable for us.
- Git branching model: Another of our main goals is agility. For that reason, we chose trunk-based development as our branching model. With this model, we ensure that we work in the main branch almost all the time. And, of course, the main branch is always production-ready.
- CI/CD: We rely on GitHub to implement our CI/CD cycles. With each pull request, all tests are executed. After merging into the main branch, new Docker images are generated and published to our private Docker registry. Finally, our Kubernetes cluster picks them up to deploy the new versions.
Hey, are you still there? Don’t lose focus. We are talking about the YepCode technology stack, so let’s start with our web-client
YepCode users only need a web browser to use the platform. We chose Next.js as our frontend framework because we love it! You probably already know this, but Next.js is based on React.js. It helps us with tedious initial and production React.js configurations.
This is one of our core technologies for other projects, and the team has extensive expertise using it. In the past, we worked extensively with Ruby on Rails and JEE template frameworks. But in this case, we picked this framework that allows us to quickly achieve any needed feature.
We also use Tailwind CSS to help us manage styles. We could use a preprocessor directly like Sass, but that requires a lot of effort to start and maintain. Tailwind CSS does all the heavy lifting for us. With very little effort, we maintain clean code and stay very agile.
We are fortunate to have a great design team that ensures that user experience and design are under control in every change. To achieve this, we rely on Figma, which allows us to share and discuss any new feature before starting to implement it.
And, what about the APIs?
When it came time to choose our API approach, we realized that different use cases require different solutions. We decided to implement a dual API strategy that provides the best of both worlds:
Frontend API (GraphQL): Our internal frontend uses a GraphQL API that we’re very comfortable with. We enjoy the flexibility that queries and mutations provide, allowing us to request only the necessary information in each React component. This approach gives us the exact data we need without over-fetching or under-fetching.
REST API: For external integrations, our SDKs and third-party developers, we provide a comprehensive REST API that follows standard REST principles. This API is fully documented with Swagger UI and allows external clients to schedule executions, create processes, review logs, and more.
This dual approach ensures that we have the right tool for each job - GraphQL for our internal frontend’s complex data requirements and REST for external integrations that need a more traditional, well-documented API approach.
MCP Tools API: For AI agents and automation workflows, we provide a Model Context Protocol (MCP) Tools API that enables seamless integration with AI assistants and LLMs. This API allows AI agents to interact with YepCode processes, execute code, and manage workflows programmatically, opening up powerful automation possibilities.
YepCode integrations
To make YepCode even more accessible and powerful, we’ve developed a comprehensive set of integration tools that enable seamless connectivity with various platforms and workflows:
yepcode-run sdk: It provides a simple and intuitive way to execute code in YepCode’s secure sandbox environment from JavaScript or Python applications. This SDK enables developers to run AI-generated code safely, execute custom scripts, and leverage YepCode’s processing capabilities from their preferred programming language. See yepcode-run (Python) and @yepcode/run (JavaScript) for more information.
YepCode Run SDK also includes a full YepCode API client, so you can use YepCode from your own code.
MCP Server: Our Model Context Protocol server implementation that allows AI agents and LLMs to interact directly with YepCode. This server exposes YepCode’s capabilities as MCP tools, enabling AI assistants to execute processes, manage workflows, and access YepCode’s features through a standardized protocol. See MCP Server blog post for more information.
These integration tools ensure that YepCode can be easily incorporated into existing workflows, regardless of the technology stack or platform being used.
The backend microservices
Our backend architecture is built around a sophisticated microservices design that separates concerns between control and execution planes. This separation ensures optimal performance, scalability, and maintainability.
Control plane
The control plane manages the orchestration and coordination of all YepCode operations:
-
API: The primary entry point for all external requests, this JEE web application is built on the Spring framework stack. It serves GraphQL API, REST API and MCP Tools API, handles authentication, rate limiting, and receives external webhook requests. As the only service exposed to the internet, it implements comprehensive security measures and request validation.
-
Engine: The central orchestrator that manages the execution lifecycle. It reads and stores from the database any information that the executors may need, maintains execution state, and coordinates between different microservices. The engine subscribes to message queues where executors publish events (logs, execution results, etc.) and publishes events for executions that need to be processed.
-
Scheduler: This critical microservice manages all time-based executions and cron jobs. It handles process scheduling using both fixed start times and cron expressions, ensuring reliable execution timing. The scheduler prepares execution contexts and coordinates with the engine to trigger processes at the appropriate times.
-
YepCode Storage: Manages persistent file storage for user executions with enterprise-grade security. It provides a unified interface for storing and retrieving files, supporting multiple cloud storage providers like AWS S3 and Google Cloud Storage. The service ensures data durability, availability, and secure access patterns. See YepCode Storage for more information.
Execution plane
The execution plane handles the actual processing of user code in isolated, secure environments:
-
Instances Operator: This intelligent microservice orchestrates the execution infrastructure by dynamically managing the number of execution instances based on demand. It continuously monitors performance metrics and automatically scales instances up or down to optimize resource utilization and ensure optimal performance. The operator also performs health checks on running instances and handles rolling updates to deploy new versions without service interruption, ensuring zero-downtime deployments.
-
Executor Manager: Acts as the execution coordinator, receiving execution requests from the engine and managing the lifecycle of process executions.
-
Executor: The core execution engine that runs user processes in isolated Firecracker microVMs. Each executor instance provides a secure, sandboxed environment where user code can run safely without affecting other processes or the underlying infrastructure.
-
Dependencies Manager: Manages the complex dependency ecosystem for user processes. It downloads and caches dependencies, ensuring they’re available to executors when needed.
-
YepCode Datastore: Provides persistent key-value storage for user processes, enabling data sharing between executions and maintaining state across process runs. See YepCode Datastore for more information.
How AAA has been solved?
We don’t like to reinvent the wheel, and since we have been using Keycloak as an identity and access management solution for years, we’re continuing with that approach. This open-source project is our core for authentication, authorization, and accounting.
Persistence: MongoDB to the rescue
Another significant decision (perhaps one of the greatest dilemmas in every software application) is which solution to use for data storage. A relational database could be used, but the documents we have to store are quite large, and the most common retrieval is by key. So, we decided to choose a NoSQL database that stores information in JSON documents as the best option.
Among all the excellent software projects that fit that NoSQL approach, we picked MongoDB. This choice was primarily driven by our experience with it and because it’s one of the core solutions present in the high availability cluster where YepCode runs.
And what about the metal that allows running all this stuff
We have also been working with Docker and Kubernetes solutions for years, and we’re very comfortable with them. So with YepCode, we continue with those DevOps solutions.
In our cluster, we enjoy high availability features. Each microservice can scale to accommodate any increased workload. Additionally, we have high availability and redundancy in the persistence layer, but we prefer to tell you about this in another article 🤓
Security and Sandboxing: Firecracker for isolated executions
Security is paramount when running user-generated code in a multi-tenant environment. We solved the sandboxing challenge using Firecracker, an open-source virtualization technology that enables secure and fast microVMs.
Firecracker provides the perfect balance between security and performance. Each process execution runs in its own isolated microVM, ensuring complete isolation between different users and processes. This approach gives us:
- Complete isolation: Each execution runs in its own virtual machine, preventing any cross-contamination between processes
- Fast startup times: Firecracker microVMs start in milliseconds, much faster than traditional VMs
- Resource efficiency: Lightweight virtualization that doesn’t consume excessive resources
- Security by design: Built-in security features that prevent unauthorized access to the host system
This sandboxing approach ensures that even if malicious code is executed, it cannot access other users’ data or compromise the underlying infrastructure. The microVM approach provides the same level of security as traditional VMs but with the performance characteristics of containers.
Our executors leverage Firecracker to create these isolated environments dynamically, ensuring that every process execution is completely secure and isolated from the rest of the system.